|
zizou ★ Plzeň, Czech Republic, 2017-02-05 03:03 (2628 d 07:55 ago) Posting: # 17014 Views: 28,406 |
|
|
Hi everybody and nobody. It was mentioned here several times that Danish Medicines Agency has one more requirement for BE: "In the opinion of the Danish Medicines Agency, the 90 % confidence intervals for the ratio of the test and reference products should include 100 %, regardless that the acceptance limits are within 80.00-125.00 % or a narrower interval. Deviations are usually only accepted if it can be adequately proved that the deviation has no clinically relevant impact on the efficacy and safety of the medicinal product." source (bolded by me) Btw. FDA document (Guidance for Industry: Bioavailability and Bioequivalence Studies for Orally Administered Drug Products - General Considerations) states in section II. BACKGROUND: C. Bioequivalence When value 1 is outside of 90% CI of GMR then there is a significant difference (maybe except for some border cases). - End of fun, of course this statistically significant difference is not relevant for FDA according to other statements requiring the confidence interval in the BE limits. On the other hand, if some new regulatory reader is suprised with the significant difference between IMPs (acc. to ANOVA p value) and ask for justification. He would be probably shocked by the answer: "It is not possible to plan the BE study with assumention of GMR=0.95, CV=x%, 90% CI in 0.8-1.25 and not significant treatment effect for power at least 80%." Maybe, Denmark has the requirement as a way to keep "Forced BE" away. (Sounds good, until the problems appear and it can filter not only "Forced BE" as everyone knows.) Nevertheless the EMA's statement "The number of subjects to be included in the study should be based on an appropriate sample size calculation." should be sufficient (to keep "Forced BE" away), if controlled correctly. (Many of regulatory authorities think that sample size is issue of ethical committees. Many of ethical committees are not able to assess the sample size estimation.) Back to the future: Should be the requirement of the inclusion of 100% in 90% CI included in the sample size estimation? (I would bet it has never been used.) ... It's quite problematic task. (So this post is only for interest to know. - I can not imagine the actual use after I made some power analysis.) One issue is that with increasing sample size we will get 100% out of 90% CI (Helmut the Hero showed it graphically here). Another issue is that test and reference products can differ (eg. the assayed content can differ up to 5%, even if the difference is zero (according to CoAs), there is some analytical accuracy, etc.), so it is usual to use null ratio 0.95 for sample size estimation (and possible worse ratio to 0.9 as option - discussed here). (Null ratio 0.90 would be unlucky coin flipping for Denmark.) I performed some simulations for power (with added condition of 1 in 90% CI to the condition of 90% CI in 0.8-1.25 (in counting step)). So I can share my figures (more accurately levelplots) for different null ratio (expected GMR used for power estimation via simulations): GMR = 0.95 GMR = 0.96![[image]](img/uploaded/image416.png) ![[image]](img/uploaded/image417.png) ![[image]](img/uploaded/image430.png) For GMR = 0.95 (left side) the maximum simulated power is 0.7809. (For n 12-80 and CV 1-50 maximum simulated power for GMR=0.95 is 0.7888.) Nice to know that with all these requirements+assumptions the power is below 80%. (Or at least seems to be acc. to simulations.) GMR = 0.97 GMR = 0.98![[image]](img/uploaded/image418.png) ![[image]](img/uploaded/image419.png) GMR = 0.99 GMR = 1![[image]](img/uploaded/image420.png) ![[image]](img/uploaded/image421.png) For GMR = 1 (right side) the maximum simulated power is 0.9016. Green columns are little defect due to I decided to move set.seed function into loops (so same seed was used for each combination of n and intra-subject CV, which looks better for smooth color transitions. And I decided to use only 20 colors for easy to see which value is over 80% and which over 90%. So I prepare two additional figures.) The darker green columns are saying that values are in 0.9-0.95, but the values are close to 0.9, and similar issue in the lighter green category 0.85-0.9 - almost in whole green region all values are really close to 0.9.) And columns appeared because n+2 makes little bit more change than CV+1 (with the same seed used). GMR = 1 (additional 1) GMR = 1 (additional 2)![[image]](img/uploaded/image422.png) ![[image]](img/uploaded/image423.png) GMR = 1 - additional 1 (left side): Function set.seed is still in loops so there is trend in coloring. (Green color is close to 0.9 in the scale.) GMR = 1 - additional 2 (right side): Function set.seed moved before loops so values are over 90% randomly - it's the same as using of different seed for each combo of n and CV. (Actually there are many of values around 90% power - simulated values are sometimes little bit over 90% - because it is not exact method of course.) For GMR = 1 (right side, with set.seed before loops) the maximum simulated power is 0.9073. Null GMR 1, max power 0.90 with alpha 0.05. The simulations confirm what I never thought about but what everyone can expect. Really scary when sponsor wants to plan the BE study with power 90%. You must expect the GMR value equal to 1 and anyway power 90% is just a theoretical maximum, in practice the power is always lower than 90%. Moreover I ignore that this should be valid for two PK metrics (AUC and Cmax). GMR = 0.9
For GMR = 0.9 the maximum simulated power is 0.4757. Little bit going to extreme n and CV (presented twice - 1) on the left to easy see categories; 2) on the right as presentable;) GMR = 0.95 (20 colors) GMR = 0.95 (200 colors)![[image]](img/uploaded/image425.png) ![[image]](img/uploaded/image426.png) For GMR = 0.95 the maximum simulated power is 0.8012 (n=12-480 and CV=1-300%). It can be over 0.8 only due to lucky number as a seed used in simulations, etc.. With comparison to EMA: (I used the same simulations as for Denmark requirement "1 in 90% CI in 0.8-1.25", although exact method exist for standard "90% CI in 0.8-1.25"). GMR = 1: ![[image]](img/uploaded/image427.png) Green area: For Denmark almost 90% power, standardly almost 100% power. It's a big difference! GMR = 0.95: ![[image]](img/uploaded/image428.png) No green area for Denmark at all! GMR = 0.9: ![[image]](img/uploaded/image429.png) No comment! Coded (with the use of function provided by Hero d_labes here) as:
power.sim2x2 <- function(CV, GMR, n, nsims=1E4, alpha=0.05, lBEL=0.8, uBEL=1.25, details=FALSE)In this case, it's more than true to say: Power. That which statisticians are always calculating Wingardium Leviosa, zizou |
![[image]](img/uploaded/image424.png)
|
Helmut ★★★  Vienna, Austria, 2017-02-05 20:16 (2627 d 14:42 ago) @ zizou Posting: # 17015 Views: 25,916 |
|
![[image]](img/uploaded/image327.png) Hi zizou, Hi zizou,what a fantastic post deserving a barnstar! First comments (others later, time allowing). ❝ FDA […] states in section II. BACKGROUND: C. Bioequivalence ❝ Bioequivalence is defined in § 320.1 as: ❝ the absence of a significant difference in the rate and extent to which the active ingredient or active moiety in pharmaceutical equivalents or pharmaceutical alternatives becomes available at the site of drug action when administered at the same molar dose under similar conditions in an appropriately designed study. ❝ When value 1 is outside of 90% CI of GMR then there is a significant difference (maybe except for some border cases). - End of fun, of course this statistically significant difference is not relevant for FDA according to other statements requiring the confidence interval in the BE limits. The guidance quotes the definition given in the 21CFR320.1. Hence, it refers to a law. Difficult to change (if you are not Mr Trump). I guess it goes back to the 1980s where no statistics were used at all (the crazy 75/75-rule). Therefore, I also guess that significant is not meant in the statistical sense. Merriam-Webster tells me:
❝ Nevertheless the EMA's statement "The number of subjects to be included in the study should be based on an appropriate sample size calculation." should be sufficient (to keep "Forced BE" away), if controlled correctly. This “appropriate” drives me nuts. Borrowed from ICH-E9. All previous versions of the BE-GL (or NfG) were better in this respect, IMHO. ❝ (Many of regulatory authorities think that sample size is issue of ethical committees. Many of ethical committees are not able to assess the sample size estimation.) Yes to both. ❝ Should be the requirement of the inclusion of 100% in 90% CI included in the sample size estimation? (I would bet it has never been used.) ... It's quite problematic task. ❝ (So this post is only for interest to know. - I can not imagine the actual use after I made some power analysis.) You are not the first. Another hero of Danish ancestry (ElMaestro) came up with some nice compiled C-code already in 2009. Download EFG and play with it.T/R 0.95, CV 30%, n 40, 1 mio sim’s give: EFG2.01 Brute force Power for BE: 81.6035, Power in Denmark: 76.5942 PowerTOST: 81.5845, Power.TOST.sim: 81.5615, your code for the ‘PE-rule’: 76.5145 Quick & extremely dirty: library(PowerTOST)I had some problems in Denmark with drugs of extremely low variability (<10%). Studies ‘overpowered’ even with the minimum acceptable sample size n=12. Stated in the protocol that I’ll expect a significant difference. In my case it was not BE (line extensions, formulation changes) and patients are dose-titrated (high between subject variability). No questions from the Vikings ever since. ❝ You discovered that spaces are necessary in CV[ i ].  Now you learned the hard way why I made it my habit to start loops with the index j.i in square brackets is one of the BBCodes used in the forum’s scripts (see also here).— Dif-tor heh smusma 🖖🏼 Довге життя Україна! ![[image]](https://static.bebac.at/pics/Blue_and_yellow_ribbon_UA.png) Helmut Schütz ![[image]](https://static.bebac.at/img/CC by.png) The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |
|
ElMaestro ★★★ Denmark, 2017-02-05 22:15 (2627 d 12:43 ago) @ Helmut Posting: # 17016 Views: 25,520 |
|
|
Hi Hötzi, ❝ Quick & extremely dirty: ❝ ❝ 100*power.TOST(alpha=0.5, CV=0.3, theta0=0.95, n=40, theta1=0.8, theta2=1)-1.25 ❝ # [1] 76.57964 I can't follow this, alpha 0.5? Substraction of 1.25% somehow from ... what? Instead, I propose something along the lines of: pwrDK222BE=function(alpha, CV, theta0, theta1, theta2, n)[1] 0.7652256— Pass or fail! ElMaestro |
|
Helmut ★★★ Vienna, Austria, 2017-02-06 14:27 (2626 d 20:31 ago) @ ElMaestro Posting: # 17019 Views: 25,677 |
|
|
Hi ElMaestro, ❝ ❝ Quick & extremely dirty: ❝ ❝ ❝ ❝ 100*power.TOST(alpha=0.5, CV=0.3, theta0=0.95, n=40, theta1=0.8, theta2=1)-1.25 ❝ ❝ # [1] 76.57964 ❝ ❝ I can't follow this, alpha 0.5? This was an insider’s joke in the ‘spirit’ of this thread. ❝ Substraction of 1.25% somehow from ... what? My personal constant to get a nice value. ❝ Instead, I propose something along the lines of: […] Yes, sure. I guess this is what you have done in EFG? — Dif-tor heh smusma 🖖🏼 Довге життя Україна! Helmut Schütz The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |
|
ElMaestro ★★★ Denmark, 2017-02-06 14:46 (2626 d 20:12 ago) @ Helmut Posting: # 17020 Views: 25,550 |
|
|
Hi Hötzi, thanks for clarification. I am sorry I did not get it. Happens often. ❝ Yes, sure. I guess this is what you have done in EFG? Not quite; when I made EFG I also believed what I was told (apparently quoting from an FDA pres. somewhere, which I don't have) that it was not possible to calculate the power / sample size in the presence of a significant treatment effect. So in my EFG implementation I used simulation. Later I decided we don't all to be sheep and refuted FDA's statement with three lines of code. Too bad I can't find the original presentation or statement from FDA anywhere .I hope the idea in the code above is clear enough that simulations won't be necessary. Finally, the wording from DKMA's side is certainly a bit backward or dubious, but DKMA are currently to the best of my knowledge only enforcing the requirement in relation to substitution. Proof of BE and approval does not hinge on a CI including 1.0. I heard in my local supermarket that they are fully aware they'd be smashed totally flat if they had to convince anyone in a referral that a treatment effect precludes a conclusion of BE. — Pass or fail! ElMaestro |
|
Helmut ★★★ Vienna, Austria, 2017-02-07 16:23 (2625 d 18:35 ago) @ ElMaestro Posting: # 17031 Views: 25,308 |
|
|
Hi ElMaestro, ❝ […] DKMA are currently to the best of my knowledge only enforcing the requirement in relation to substitution. Seems so. Acceptance limits for AUC and Cmax of antiepileptics apart from levetiracetam and benzodiazepines are 90.00-111.11%. Now we could ask what is the maximum deviation of the PE from 100% for a given sample size (based on CV and target power). Example valproic acid, CV for Cmax 10% (AUC 5–7%), target power 80%, θ0 0.975 (as suggested by the FDA; tighter release spec’s for NTIDs):
That’s tough. The “conventional” sample size would be 22. To fulfill the Danish requirement the GMR must not be outside 0.9817…1.0186 without compromising power. Wow. if we want higher power we soon discover that the GMR must be exactly 1. Side effect: If we originally assumed a GMR of 0.95 (n 44), the GMR range has to be even tighter with 0.9834…1.0169 since Danish power decreases with the sample size (see the second plot in this post). — Dif-tor heh smusma 🖖🏼 Довге життя Україна! Helmut Schütz The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |
|
d_labes ★★★ Berlin, Germany, 2017-02-08 11:57 (2624 d 23:01 ago) @ Helmut Posting: # 17038 Views: 24,830 |
|
|
Dear Helmut! Side effect 2: The Danish are ultra-conservative! With your settings and ElMaestro's code: pwrDK222BE(alpha=0.05, CV=0.1, n=22, theta0=0.9, theta1=0.9)Something wrong with the forum? It kicks me out nearly all the time. — Regards, Detlew |
|
Helmut ★★★ Vienna, Austria, 2017-02-08 12:47 (2624 d 22:11 ago) @ d_labes Posting: # 17039 Views: 25,028 |
|
|
Dear Detlew, ❝ Side effect 2: ❝ The Danish are ultra-conservative! Confirmed. Try this one:
It is courageous to assume theta0 0.9 for a NTID ( sampleN.TOST() would tell you to get lost). If you believe in 0.95, n would be 44. To get 80% power the GMR-range is 0.9834…1.0169. Power for 0.95 is only 0.2333. Would it be ethical to perform the study?❝ Something wrong with the forum? It kicks me out nearly all the time. You are not alone.  See this post. See this post.— Dif-tor heh smusma 🖖🏼 Довге життя Україна! Helmut Schütz The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |
|
d_labes ★★★ Berlin, Germany, 2017-02-06 16:06 (2626 d 18:52 ago) @ ElMaestro Posting: # 17023 Views: 25,408 |
|
|
Dear ElMaestro, ❝ ... ❝ Instead, I propose something along the lines of: ❝ ❝ ... If that is really correct (what I can't verify due to a walnut-sized brain) it deserves also a barnstar  ! !— Regards, Detlew |
|
Helmut ★★★ Vienna, Austria, 2017-02-06 18:16 (2626 d 16:42 ago) @ d_labes Posting: # 17024 Views: 25,500 |
|
|
Dear Detlew, ❝ If that is really correct (what I can't verify due to a walnut-sized brain) it deserves also a barnstar Plausible to me. When I compared zizou’s results for GMR 0.95, n 24, CV 0.1–0.3 (nsims=1E6) with our Captain’s I got:
— Dif-tor heh smusma 🖖🏼 Довге життя Україна! Helmut Schütz The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |
|
d_labes ★★★ Berlin, Germany, 2017-02-06 21:25 (2626 d 13:33 ago) @ Helmut Posting: # 17025 Views: 25,462 |
|
|
Dear Helmut, ❝ Plausible to me. Here we are two! But plausible isn't a proof of truth. And that proof is too much for my brain. Remember: I'm only a run-of-the-mill statistician aka "Applied statistician. A second class statistician who imagines that he is a first class scientist." © Stephen Senn. — Regards, Detlew |
|
ElMaestro ★★★ Denmark, 2017-02-06 23:30 (2626 d 11:28 ago) @ d_labes Posting: # 17026 Views: 25,743 |
|
|
Let P0= P(GMR<U)-P(GMR<L) regardless of what U and L are, as long as they are meaningful (U>L, and not negative). This quantitiy is easuily accessible via Power.TOST. If L and U are BE acceptance limits then P0 is power in a BE trial. We can rewrite that as P0=P(GMR in [L,U]), regardless of what U and L are, as long as they are meaningful (U>L, and not negative) If we define L=0.8 and U=1.25 and GMR is within these limits, then we can say that P0 falls in (is composed of) three categories: 1. Those that have GMR in [L, 1.0] 2. Those that have GMR in [1.0, U] 3. Anything that isn’t 1 or 2. Because “3” is anything else than 1 or 2, P1+P2+P3=P0. and because 1 and 2 are mutually exclusive (can’t fall in both categories), except the zero-prob of GMR exactly 1.0. P1 and P2 are meaningfully additive, and P1+P2 will thus be the probability of having a passing study in which 1.0 isn’t in the acceptance range when L=0.8 and U=1.25. The probability we are looking for is P3, because this is a study fulfiling P(GMR in [L,U]) but not those that have GMR in [L, 1.0] and not those that have GMR in [1.0, U], therefore P3=P0-P1-P2, so we just plug in the relevant limits in Power.TOST and Bob’s your uncle. — Pass or fail! ElMaestro |
|
zizou ★ Plzeň, Czech Republic, 2017-02-06 23:42 (2626 d 11:16 ago) @ d_labes Posting: # 17027 Views: 25,153 |
|
|
Dear all. It's exact! Power is nothing else than probability. Simple example: You have 1 dice and you roll once: Similarly you have probability that 90% CI is in 80-100% (without 100%) = P1, probability that 90% CI is in 100%-125% (without 100%) = P2, then there is option when 90% CI is in 80-125% a 100% is in the 90% CI = P3, there is nothing more (no other option which can happen), so the sum is the Classical Power (probability that you have 90% CI in 80-125%). Classical Power=P1+P2+P3, where P3 is pwrDK222BE = Classical Power - P1 - P2. P.S. ElMaestro was faster than me (but because I wrote it in different wording, I am posting it too ... hope for better understanding maybe) |
|
d_labes ★★★ Berlin, Germany, 2017-02-07 11:01 (2625 d 23:57 ago) @ zizou Posting: # 17028 Views: 25,018 |
|
|
Dear ElMaestro, dear zizou! Thanks for educating me  . .— Regards, Detlew |
|
Helmut ★★★ Vienna, Austria, 2017-02-06 14:47 (2626 d 20:12 ago) @ zizou Posting: # 17021 Views: 25,936 |
|
|
Hi zizou, ❝ I know, someone can do it better (eg. in 3D like this kind of figure). Your wish is my command. 3D-plots for GMR 0.95. Not sure whether they are more informative than yours. Conventional BE (rest of the world) I know only a few sample sizes by heart. One is for GMR 0.95, CV 30%, and target power 80%: 40 (expected power 81.6%). For Denmark with n=40 we get a mere 76.5%. Note the red contour lines at 70% power. As you discovered as well we never reach 80%. Fascinating the behavior at low CVs. If we increase the sample size, power decreases because a significant difference gets more likely. What a mess. — Dif-tor heh smusma 🖖🏼 Довге життя Україна! Helmut Schütz The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |
![[image]](img/uploaded/image431.png)
![[image]](img/uploaded/image432.png)
|
d_labes ★★★ Berlin, Germany, 2017-02-06 15:54 (2626 d 19:04 ago) @ zizou Posting: # 17022 Views: 25,500 |
|
|
Dear zizou, what a laborious task!  One minor comment to your code: The number of sims you used ( 1e4 as far as I could see) is a little bit low. Especially if you come into regions with power <=0.05.Another comment to the Danish requirement: Already in the early days of the evolution of (bio)equivalence tests it was dicovered that another construction of the CI may be used, namely
low and high are the conventional confidence interval limits.This construction of the CI always contains GMR=1 and corresponds - like the conventional CI - to a size alpha TOST. This observation makes the Danish requirement statistical nonsense. Unfortunately this alternative CI hasn't got further support in the history. Berger, Hsu "Bioequivalence Trials, Intersection-Union Tests and Equivalence Confidence Sets" Statist. Sci. Volume 11, Number 4 (1996), 283-319. See also here. — Regards, Detlew |
|
zizou ★ Plzeň, Czech Republic, 2017-02-08 22:03 (2624 d 12:55 ago) @ d_labes Posting: # 17040 Views: 25,406 |
|
|
Dear d_labes, thanks for comments (especially for the second). ❝ One minor comment to your code: ❝ The number of sims you used ( You are right. I did the code faster for testing and unfortunately I forgot to change it to the higher number before producing figures. Nevertheless it was enough for the purpose of the post (combined with not much important subject of the post). Additionally all <=0.05 values were black in the levelplots, and I was much more interested in the power about 80 or close to 90%. ❝ Another comment to the Danish requirement: ❝ ... that another construction of the CI may be used, namely
❝ where
❝ This observation makes the Danish requirement statistical nonsense. The property of extending CI to include 100% without adjusting the alpha is interesting. I had to remind myself what the confidence interval means. I always slide in mind to probability which is common misunderstanding - citation: "A 95% confidence interval does not mean that for a given realised interval calculated from sample data there is a 95% probability the population parameter lies within the interval. Once an experiment is done and an interval calculated, this interval either covers the parameter value or it does not; it is no longer a matter of probability. The 95% probability relates to the reliability of the estimation procedure, not to a specific calculated interval." If it was probability (but it is not), the change of 90% CI would be to the something between 90-95% CI. For example 90% CI 87-98%, then there would be probability 5% that true GMR value is outside of the 90% CI lower and 5% outside higher. When no change of lower limit of 90% CI and adding some values up to value 100% to create a new CI, there would still be 5% probability to have true GMR lower and several percent probability to have true GMR higher than 100%. - Text in red is wrong (it's how the CI may be wrongly understood).1) When we are constructing classical 90% CI (alpha=0.05) - the 90% of hypothetically observed confidence intervals contains the true GMR. 2) When we are constructing alternative 95% CI (alpha=0.05) - the 95% of hypothetically observed alternative confidence intervals contains the true GMR, where alternative 95% CI is classical 90% CI extended to 100% value. So when we use the second CI construction according to the references mentioned by d_labes (as standard 90% CI extended to have 100% in), we get 95% CI (with assumption that true GMR is not equal to 100% - it's not limiting us, in that case we get the best CI (i.e. 100% CI)). ❝ See also here. I tried simulations (with patience) (and with reading the steps to find out what was done there), nevertheless I failed to get reported results (with seed after the # symbol). mean(coverge.ci90) # ci90 is the classical 90% CI for difference T-R |
|
d_labes ★★★ Berlin, Germany, 2017-02-09 12:18 (2623 d 22:40 ago) @ zizou Posting: # 17041 Views: 25,097 |
|
|
Dear zizou, all you have written about CI(s) is more or less correct. But it's a misunderstanding. The basic test to use for the BE decision is TOST with alpha = 0.05 by convention. And this is operationally identical to the interval inclusion rule, conventionally using an ordinary 1-2*alpha CI. The Berger, Hsu alternative CI+ is another CI (an 1-alpha CI) constructed based on TOST and gives the same result if used as decision rule for stating BE. Code to show this via simulations: power.sim2x2 <- function(CV, GMR, n, nsims=1E5, alpha=0.05, lBEL=0.8, uBEL=1.25, And now try: power.sim2x2(CV=0.2, n=24, GMR=0.95, CItype="usual")Quod errat demonstrandum. At least for CV=0.2, n=24 and GMR=0.95 .BTW: It's not necessary to rely on simulations. The EMA BSWP f.i. doesn't like simulations  . You may consider different cases for lCL, uCL to show that the alternative CI+ gives always the same decision as the usual 1-2*alpha CI. . You may consider different cases for lCL, uCL to show that the alternative CI+ gives always the same decision as the usual 1-2*alpha CI. F.i.: If the usual CI is within the acceptance range (with upper CL below 1) -> decide BE Then the alternative CI with upper CL set to 1 is also in the acceptance range -> decide BE. And so on for other constellations. — Regards, Detlew |
|
ElMaestro ★★★ Denmark, 2017-02-09 12:36 (2623 d 22:22 ago) @ d_labes Posting: # 17042 Views: 24,932 |
|
|
Dear Detlefffffff, I am with zizuo here. ❝ all you have written about CI(s) is more or less correct. ❝ But it's a misunderstanding. No, it is an understanding, and it is a case of seeing things in another and very healthy perspective.  ❝ The basic test to use for the BE decision is TOST with alpha = 0.05 by convention. And this is operationally identical to the interval inclusion rule, conventionally using an ordinary 1-2*alpha CI. You are right, the conclusion is the same, but that is about it. The rest is to me pure and simple garbage; don't get me wrong, I am not criticising you but rather the inventor of the idea. If someone reports a CI of 0.8456-1.0000 to me, then it might in actuality imply a 90% CI of 0.8456-0.98765 or whatever. Is that science? In a sense it makes no difference as the product is approved, but hey why bother at all then with this adjustment. Why not just go all the way and adjust all CI's so that they span across 1.0 like...what was his name... some statistician twenty-thirty years ago.... his name was Lester Hamsterballs or something...? Now if you will excuse me, I need to leave; I have to go to the supermarket now and buy a liter of milk. The ordinary price is 0.8 Euros but I only have half a Euro. So I think I will argue that the price needs to be adjusted to my buying power, or that my 0.5 Euro coin represents a value of 0.8. I am sure the "customer service relations manager", or whatevertheheck the guy behind the till is called, will agree. Why wouldn't he?! — Pass or fail! ElMaestro |
|
d_labes ★★★ Berlin, Germany, 2017-02-09 12:48 (2623 d 22:10 ago) @ ElMaestro Posting: # 17043 Views: 24,827 |
|
|
Dear ElMeastro, to like the idea of Berger/Hsu or not is up to you. But to like or not is not the question. — Regards, Detlew |
|
ElMaestro ★★★ Denmark, 2017-02-09 14:28 (2623 d 20:31 ago) @ d_labes Posting: # 17044 Views: 24,841 |
|
|
How decidedly odd, the guy behind the till did not allow me to leave the shop with a liter of milk against payment of 0.5 Euros?! And here I thought I had developed the perfect protocol. This was totally unexpected. I wonder what went wrong. Must talk to my psychiatrist so that I do not suffer a trauma. — Pass or fail! ElMaestro |
|
zizou ★ Plzeň, Czech Republic, 2017-02-09 15:42 (2623 d 19:17 ago) @ ElMaestro Posting: # 17046 Views: 25,042 |
|
|
Dear ElMaestro, what a pity, maybe it was not the perfect protocol. Look at this: We could go further. Maybe you meant so, as you wrote: ❝ Why not just go all the way and adjust all CI's so that they span across 1.0 ... Nevertheless what about another alternative CI (sometimes 1-alpha CI, sometimes 100% CI, and sometimes something between) which is constructed based on TOST and BE decision is not affected as well.
low and high are the classical 90% confidence interval limits.I added the CI.9x to simulations (Aaron Zeng R code for TOST CI simulation): set.seed(20140313)So when we let the 90% CI go, we can have nice (9x%) CI around 1, with alpha 0.05. Pretty! ... Or ... Pretty nasty! ElMaestro: You should try to buy a liter of milk for 1 Euro to verify this. |
|
Helmut ★★★ Vienna, Austria, 2017-02-09 14:41 (2623 d 20:17 ago) @ ElMaestro Posting: # 17045 Views: 24,893 |
|
|
Hi ElMaestro, ❝ If someone reports a CI of 0.8456-1.0000 to me, then it might in actuality imply a 90% CI of 0.8456-0.98765 or whatever. Is that science? As zizou noted above it is less informative than the conventional (shortest) CI – we only know that the GMR is <1 – and we can’t calculate the CV from the CI any more. ❝ Why not just go all the way and adjust all CI's so that they span across 1.0 like...what was his name... some statistician twenty-thirty years ago.... his name was Lester Hamsterballs or something...? 41 years ago. Westlake. Wilfred J. Westlake. Took me ages to persuade Pharsight/Certara to remove it from the standard output of WinNonlin (available till v6.3). — Dif-tor heh smusma 🖖🏼 Довге життя Україна! Helmut Schütz The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |
|
d_labes ★★★ Berlin, Germany, 2017-02-09 21:37 (2623 d 13:21 ago) @ Helmut Posting: # 17047 Views: 24,828 |
|
|
Dear Helmut! ❝ As zizou noted above it is less informative than the conventional (shortest) CI Ever used the 'more informative' feature really? Beside the need to answer questions "Why does the CI not covering 1" aka "please discuss the significant treatment effect"? And answering along the line "significant treatment effect is not the question to be answered in an equivalence trial and therefore not relevant"? ❝ – we only know that the GMR is <1 - and we can’t calculate the CV from the CI any more. Really? Why not? I could and PowerTOST also, presumed I have the point estimate at hand.Additionally being able to re-calculate the CV from the CI is a "nice to have", but not a pre-requisite for a valid decision procedure of the (bio)equivalence. To be clear: I don't advocate to use the alternative CI. It has it's pros and cons like the conventional 1-2*alpha CI also has it's pros and cons. See the Berger/Hsu paper and similar research. But it illustrates in my opinion that the request "GMR=1 has to be in the (whatever) CI" is superflous. It may be included in the BE devision via that alternative CI in a straight forward matter or if included in the conventional CI lead to a BE decision procedure with horrible power and ultra-conservative type I error as zizou has excellently schown and as we dicussed above. Features which renders this BE decision procedure as nearly unfeasible. Moreover: The 1-2*alpha CI has made it, in the community of BE researchers as well as into the regulatory boddies. Thus we have no choice ... Whatever we like or like not. We are all sheeps ... So much ado for nothing. Drink milk or better drink a good Czech beer, preferrably from zizou's home  . .— Regards, Detlew |
|
ElMaestro ★★★ Denmark, 2017-02-10 14:51 (2622 d 20:07 ago) @ d_labes Posting: # 17048 Views: 24,539 |
|
|
Hi Detlefff and all, ❝ So much ado for nothing. Wise words. I think Denmark in the grand scheme of things amounts to very little, and it isn't a market that is particularly appealing to the guys in Armani suits. This case has more academic importance, and is a good case for educational activities, but that is about it. ❝ Drink milk or better drink a good Czech beer, preferrably from zizou's home I will follow your recommendation. Thanks a lot. Will be departing for Prague this Sunday. — Pass or fail! ElMaestro |
|
mittyri ★★ Russia, 2017-02-10 16:28 (2622 d 18:31 ago) @ ElMaestro Posting: # 17049 Views: 24,632 |
|
|
Hi ElMaestro, ❝ Wise words. I think Denmark in the grand scheme of things amounts to very little, and it isn't a market that is particularly appealing to the guys in Armani suits. Everything could be changed very soon: Dr Senderovitz added: “The DMA is a committed partner of the EMA, and many of our employees are dedicated members of scientific committees and working groups under the EMA. “There is no doubt that Brexit will have a major impact on the cooperation on medicinal products throughout Europe, especially because the UK’s Medicines and Healthcare products Regulatory Agency is currently contributing significantly to the scientific work at the EMA. “Consequently, we are bringing more staff into our organization, and we are willing to take more than a fair share of future assessments. We are also making efforts to strengthen our capacity within scientific advice and biostatistics.”  Denmark... Why not?? — Kind regards, Mittyri |
|
d_labes ★★★ Berlin, Germany, 2017-02-10 21:10 (2622 d 13:49 ago) @ mittyri Posting: # 17051 Views: 24,441 |
|
|
Dear mittyri, ❝ ❝ Denmark... Why not?? In the light of the thread we are debating here I would opt rather for "not"! Although ElMaestro get's his liter of milk from a supermarket compatible with the Danish twist .I myself didn't drink milk at all, but rather a good beer. — Regards, Detlew |
|
d_labes ★★★ Berlin, Germany, 2017-02-10 20:57 (2622 d 14:02 ago) @ ElMaestro Posting: # 17050 Views: 24,508 |
|
|
Dear ElMaestro! ❝ ❝ Drink milk or better drink a good Czech beer, preferrably from zizou's home ❝ I will follow your recommendation. Thanks a lot. Will be departing for Prague this Sunday. A wise decision to go to Prague! But in Prague you should enjoy Staropramen (Old spring) brewed in that city. Number #one! Really! Its my body and stomach drink every evening. Also this evening! — Regards, Detlew |
|
Helmut ★★★ Vienna, Austria, 2019-11-08 13:47 (1621 d 21:11 ago) @ zizou Posting: # 20765 Views: 8,564 |
|
|
Hi zizou, everybody and nobody, sorry for excavating this one. ❝ It was mentioned here several times that Danish Medicines Agency has one more requirement for BE: ❝ "In the opinion of the Danish Medicines Agency, the 90 % confidence intervals for the ratio of the test and reference products should include 100 %, regardless that the acceptance limits are within 80.00-125.00 % or a narrower interval. Deviations are usually only accepted if it can be adequately proved that the deviation has no clinically relevant impact on the efficacy and safety of the medicinal product." source (bolded by me) This week in Athens three assessors of the Danish agency attended the training and told that this requirement is not enforced any more. Also removed from the website updated in July 2019. — Dif-tor heh smusma 🖖🏼 Довге життя Україна! Helmut Schütz The quality of responses received is directly proportional to the quality of the question asked. 🚮 Science Quotes |

 Ing. Helmut Schütz
Ing. Helmut Schütz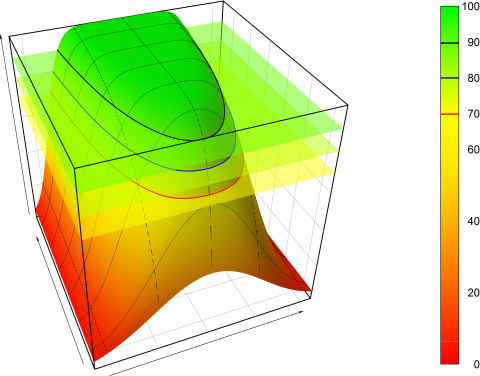{kind=link}